1. What is semantic search?
In today’s digital landscape, the volume of information available online is vast and ever-expanding. As users, we rely heavily on search engines to navigate this sea of data and retrieve the information we seek which are implemented based on full-text search models.
However, traditional keyword-based search methods (syntactic search) often fall short of accurately understanding the intent behind our queries, leading to results that may not fully meet our needs because these methods fully depend on vocabulary. Before diving into keyword-based search methods, I suggest looking at this article to learn how a basic full-text search system works.
In full-text search, synonymy and polysemy pose significant challenges to accurately retrieving relevant information:
- Synonymy: Synonymy refers to the situation where different words or phrases have the same or similar meanings. For example, “car” and “automobile” are synonyms—they refer to the same concept
- Polysemy: Polysemy arises when a single word has multiple meanings or senses. For instance, the word “bank” can refer to a financial institution, the side of a river, or even a verb meaning to tilt or incline
To resolve synonymy and polysemy problems, we need another full-text search approach to avoid depending on the vocabulary, it is semantic search.
2. Some semantic search approaches
There are many approaches to implement semantic search which can be categorized into three types:
- Explicit semantic analyst: Improving information retrieval with latent semantic indexing [Deerwester, Scott 1988], Probabilistic latent semantic indexing [Hofmann 1999], Latent dirichlet allocation [DM Blei et al. 2003], A latent semantic model with convolutional-pooling structure for information retrieval [Shen, Yelong, et al. 2014]
- Lexical database: Using wordnet to disambiguate word senses for text retrieval [Voorhees, Ellen M. 1993], Indexing with wordnet synsets can improve text retrieval [Gonzalo, Julio, et al. 1998],…
- Ontology: Concept-based search and retrieval system [Lin, Albert Deirchow 2004], Ontology-based Interpretation of Keywords for Semantic Search [Thanh Tran et al. 2007], Semantically enhanced information retrieval: An ontology-based approach [Fernández et al. 2011]
In this article, we will go through a state-of-the-art approach – using LLM to implement semantic search.
3. What is LLM?
A Large Language Model (LLM) refers to a type of artificial intelligence model designed to understand and generate human language. These models are typically based on deep learning techniques, particularly variants of recurrent neural networks (RNNs) or transformer architectures.
LLMs are trained on large amounts of text data, allowing them to learn the statistical patterns and structures of human language. They can perform a variety of natural language processing (NLP) tasks, including text generation, language translation, sentiment analysis, text summarization, and more.
One of the most well-known examples of LLMs is OpenAI’s GPT (Generative Pre-trained Transformer) series, including models like GPT-2 and GPT-3. These models have been trained on vast datasets and have achieved remarkable performance in understanding and generating human-like text across various domains.
LLMs have applications in a wide range of fields, including conversational agents, content generation, language translation, and text analysis. They have also raised ethical and societal considerations, particularly regarding issues such as bias in language generation, misuse of AI-generated content, and potential impacts on employment.
4. Semantic search with LLM
LLMs are well-suited for semantic search tasks due to their ability to understand and generate human-like language. Here’s how LLMs can be used in semantic search:
- Semantic Understanding: LLMs can be fine-tuned on specific semantic search tasks to understand the context and intent behind user queries. By leveraging the contextual understanding encoded in the model, it can better interpret the meaning of queries and match them with relevant documents.
- Document Representation: LLMs can encode documents into dense vector representations, also known as embeddings, which capture the semantic meaning of the text. These embeddings can be used to compare the semantic similarity between the query and documents, enabling more accurate retrieval of relevant content.
- Query Expansion: LLMs can generate additional contextually relevant terms for the user query, expanding the search space and potentially improving recall. By understanding the semantics of the query, the model can suggest related terms or concepts that might not be explicitly mentioned in the query but are semantically connected.
- Relevance Ranking: LLMs can score documents based on their semantic relevance to the query. By considering the semantic similarity between the query and documents, LLMs can rank search results according to their relevance, ensuring that the most relevant documents are presented to the user.
- Feedback Loop: LLMs can be integrated into feedback mechanisms where user interactions with search results are used to refine the search model iteratively. By analyzing user feedback, the model can continuously learn and improve its understanding of semantic relevance.
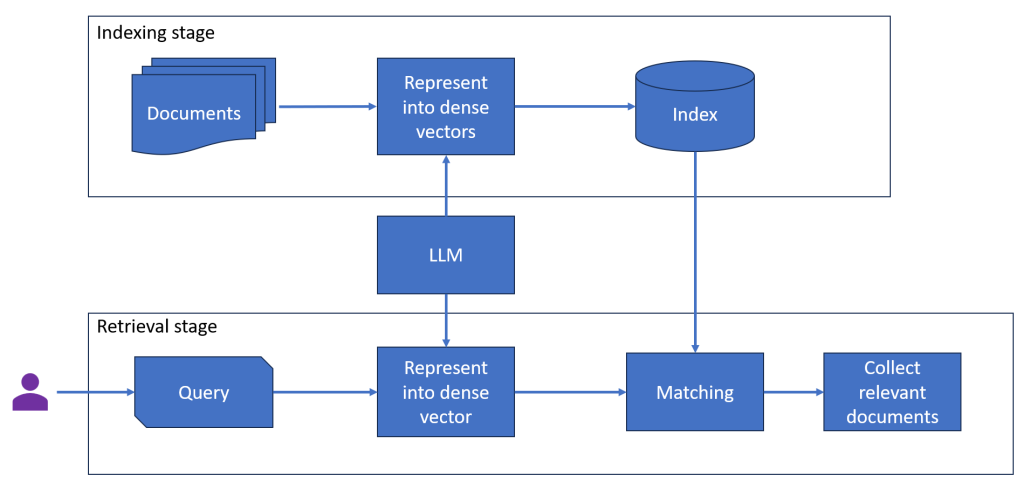
Below is a basic semantic search system using LLM that we are going to implement, both the indexing stage and the retrieval stage utilize the power of LLM to represent documents/queries into dense vectors, and then the cousin similarity will be used to measure similarity between the user query and indexed documents to collect the most relevant documents.
5. Demo
We will use SentenceTransformers as the LLM model in our semantic search applition which is a Python library and framework for training, fine-tuning, and using pre-trained models for generating embeddings from sentences or text data. SentenceTransformer was initially implemented based on BERT and supports more than 100 languages.
paraphrase-multilingual-MiniLM-L12-v2 will be used as the LLM model in our application, this model is a Multi-Lingual Model supporting 50+ languages. We will do some smoke test to verify how our semantic search application works.
5.1. Semantic search on Vietnamese
Documents: [D1 = ‘Bài hát Tết Đến Rồi’, D2 = ‘Năm nay nông dân được mùa vụ xuân hè’]
Query: ‘Ca khúc về mùa xuân’
Expected result: D1 because ‘Ca khúc’ and ‘Bài hát’ refer to the same meaning, ‘Tết’ and ‘Mùa xuân’ also refer to the same meaning. It is Synonymy problem.
Actual result:
- Syntactic search approach will return D2 since it has some similar vocabulary with the query such as ‘mùa’, ‘xuân’ but they don’t has the same meaning (Polysemy problem)
- Our semantic search application below returns D1
from sentence_transformers import SentenceTransformer, util
import torch
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
corpus = ['Bài hát Tết Đến Rồi',
'Năm nay nông dân được mùa vụ xuân hè',
]
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
query = 'Ca khúc về mùa xuân'
query_embedding = model.encode(query, convert_to_tensor=True)
cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
top_result = torch.topk(cos_scores, k=1)
print('Query sentence:')
print(query)
print('Closest match:')
print(corpus[top_result.indices[0]])
5.2. Semantic search on English
Documents: [D1 = ‘Rolling is a piano store’, D2 = ‘Financial instrument is used in finance to describe contracts’]
Query: ‘Where to buy musical instrument?’
Expected result: D1 because ‘piano’ is an ‘musical instrument’
Actual result:
- Syntactic search approach will return D2 since it has some similar vocabulary with the query such as ‘instrument’, ‘to’
- Our semantic search appliacation below returns D1
from sentence_transformers import SentenceTransformer, util
import torch
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
corpus = ['Rolling is a piano store',
'Financial instrument is used in finance to describe contracts',
]
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
query = 'Where to buy musical instrument?'
query_embedding = model.encode(query, convert_to_tensor=True)
cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]
top_result = torch.topk(cos_scores, k=1)
print('Query sentence:')
print(query)
print('Closest match:')
print(corpus[top_result.indices[0]])
6. Conclusion
In conclusion, our simple semantic search approach powered by LLM represents a significant advancement in information retrieval technology. By leveraging the contextual understanding and semantic capabilities of LLMs, these systems enable more accurate and intuitive search experiences.
Through the recognition of synonyms, polysemy, and context, LLM-based semantic search tools can provide users with highly relevant search results, enhancing productivity and efficiency. Moreover, the simplicity of integrating such systems into existing applications makes them accessible to a wide range of users and industries.
As research and development in LLMs continue to progress, we can expect even further improvements in semantic search capabilities, leading to more natural and intelligent interactions with digital information. This sample project can be found on GitHub.