1. Why Kafka?
Kafka is an open-source distributed event streaming platform used for building real-time data pipelines and streaming applications. Originally Kafka was developed by LinkedIn and later open-sourced as a part of the Apache Software Foundation, Apache Kafka is designed to handle high-throughput, fault-tolerant, and scalable streaming data. It’s commonly used in scenarios like Real-time Data Processing, Log Aggregation, Event Sourcing, Stream Processing, Metrics Monitoring, Data Integration, Microservices Communication, IOT, Change Data Capture, and Machine Learning Pipelines.
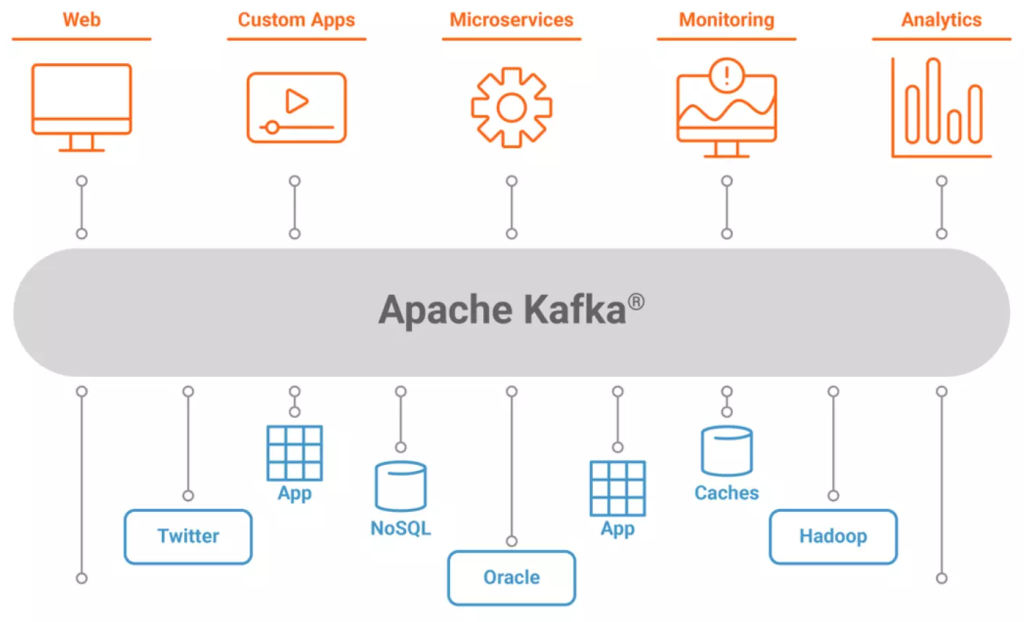
Kafka does have distinct advantages compared with other messaging systems that make it a preferred choice for certain use cases:
- Scalability: Kafka is designed to scale horizontally, allowing it to handle massive volumes of data and high-throughput workloads across distributed systems. Its architecture enables seamless scaling by adding more brokers to the cluster.
- Fault Tolerance: Kafka ensures high availability and fault tolerance by replicating data across multiple brokers in a cluster. This replication mechanism ensures that data remains available even if some nodes fail, enhancing the reliability of the system.
- Durability: Kafka persists messages to disk, providing durability and enabling consumers to replay messages if needed. This durability ensures that messages are not lost even in the event of hardware failures.
- Real-time Processing: Kafka facilitates real-time processing of streaming data, making it suitable for use cases such as real-time analytics, monitoring, and event-driven architectures. Its low latency and high throughput capabilities enable timely processing of data streams.
- Decoupled Architecture: Kafka’s decoupled architecture allows producers and consumers to operate independently, providing flexibility and scalability in designing streaming data applications. Producers can publish messages to topics without needing to know who will consume them, and consumers can subscribe to topics to receive messages of interest.
- Integration Ecosystem: Kafka has a rich ecosystem of connectors and integrations with various systems and frameworks, including stream processing engines like Apache Flink and Apache Spark, as well as storage systems like Apache Hadoop. This ecosystem facilitates seamless integration with existing infrastructure and enables the building of end-to-end data pipelines.
- Community and Support: Kafka benefits from a large and active community of developers and users, providing a wealth of resources, documentation, and community-driven support. This ecosystem contributes to the ongoing development and improvement of Kafka, ensuring its continued relevance and adoption in the industry.
2. Kafka’s architecture and basic concepts
Apache Kafka follows a distributed architecture designed for scalability, fault tolerance, and high throughput.
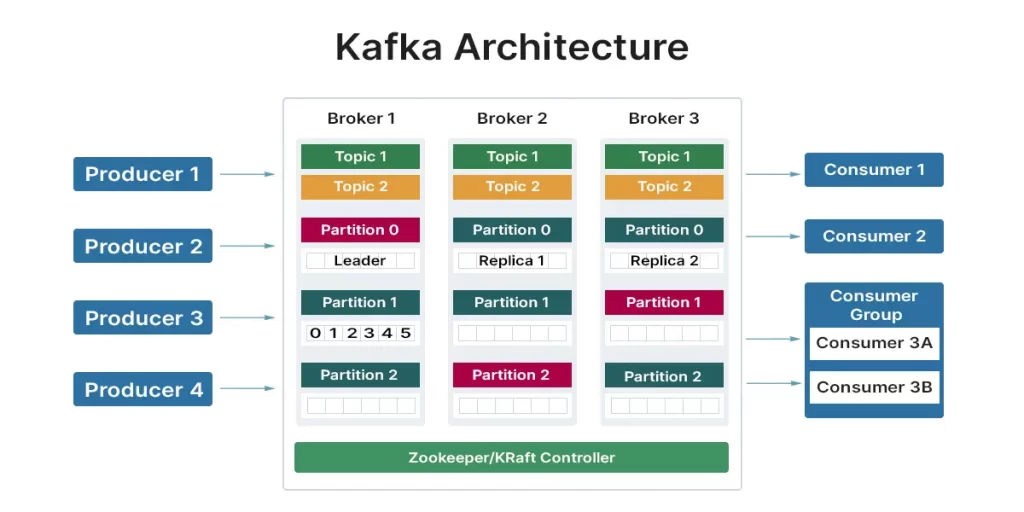
Here’s an overview of Kafka’s architecture:
- Broker:
- Kafka clusters consist of one or more Kafka brokers.
- A broker is a server responsible for storing and managing topic partitions, handling produce and consume requests, and replicating data across the cluster for fault tolerance.
- Brokers communicate with each other to ensure data replication and consistency across partitions.
- Topic:
- Topics are logical categories or feeds to which messages are published by producers and from which messages are consumed by consumers.
- Each topic is divided into one or more partitions.
- Topics can have multiple consumers (consumer groups) subscribed to them, enabling parallel message processing.
- Partition:
- Each topic is divided into one or more partitions, which are distributed across Kafka brokers in the cluster.
- Partitions are the unit of parallelism in Kafka, allowing messages within a topic to be processed concurrently by multiple consumers.
- Messages within a partition are ordered and immutable, ensuring strict message ordering and durability.
- Producer:
- Producers are client applications that publish messages to Kafka topics.
- Producers send messages to Kafka brokers, specifying the topic and optionally a message key.
- Producers can choose to receive acknowledgments (acks) from brokers to confirm successful message delivery.
- Consumer:
- Consumers are client applications that subscribe to Kafka topics and consume messages from topic partitions.
- Consumers can be organized into consumer groups, where each consumer group processes messages independently.
- Kafka provides scalable and fault-tolerant message consumption through consumer rebalancing and offset management.
- Consumer Group:
- A consumer group is a logical grouping of consumers that jointly consume messages from one or more Kafka topics.
- Each message within a topic partition is delivered to only one consumer within the group, enabling parallel message processing and load balancing across consumers.
- ZooKeeper:
- Kafka uses Apache ZooKeeper for cluster coordination, metadata management, and leader election.
- ZooKeeper maintains metadata about brokers, topics, partitions, and consumer groups, ensuring consistency and fault tolerance in the Kafka cluster.
3. Consumer and Partition relationship
In Apache Kafka, the relationship between consumers and partitions is fundamental to how messages are processed and distributed within a Kafka topic, so it is super important to understand this relationship to use Kafka in the right way.
Each Kafka topic is divided into one or more partitions. Each partition is exclusively owned by a single consumer within a consumer group. This ensures that messages within a partition are processed sequentially by a single consumer instance.
Kafka consumers provide parallelism by allowing multiple instances (consumers) within a consumer group to process messages concurrently. Each consumer within a group is assigned one or more partitions to consume messages from. The number of partitions assigned to a consumer is determined by the number of consumer instances and the partitioning strategy (e.g., round-robin, range-based) used by Kafka. Hence, Kafka dynamically rebalances partition assignments among consumer instances within a consumer group to ensure equitable distribution of workload and guarantees that messages within a partition are processed in the order they are received.
Let’s consider an example: suppose we have a Kafka cluster with one or many brokers and a topic named example_topic with three partitions (Partition0, Partition1, Partition2).
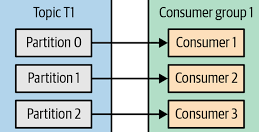
We also have a consumer group named example_group with three consumer instances (Consumer1, Consumer2, Consumer3) that belong to this group.
- Subscription:
- The consumer group coordinator receives the subscription information from the consumers in
example_group. Let’s say the subscription is for theexample_topic.
- The consumer group coordinator receives the subscription information from the consumers in
- Partition Assignment:
- Kafka uses a partition assignment strategy to determine how to distribute the partitions of
example_topicamong the consumers inexample_group. - Let’s assume Kafka uses a round-robin assignment strategy. In this case, each consumer in the group will be assigned one partition in a round-robin fashion.
- Kafka uses a partition assignment strategy to determine how to distribute the partitions of
- Partition Assignment:
- After the partition assignment is calculated, the consumer group coordinator communicates the assignments to the consumers.
- Consumer1 is assigned
Partition0, Consumer2 is assignedPartition1, and Consumer3 is assignedPartition2.
- Consumption:
- Each consumer starts consuming messages from the partition(s) it was assigned.
- Consumer1 consumes messages from
Partition0, Consumer2 consumes messages fromPartition1, and Consumer3 consumes messages fromPartition2. - Messages within each partition are processed sequentially by the assigned consumer.
- Rebalancing:
- If a new consumer joins the group or an existing consumer leaves, Kafka triggers a rebalance operation.
- During rebalancing, the partition assignments are recalculated, and partitions may be reassigned among the consumers to maintain load balance and fault tolerance.
4. Schema Registry
Kafka Schema Registry is a centralized service used in Apache Kafka ecosystems to manage schemas for data serialization and deserialization. It provides a repository for storing and managing Avro or other schema formats used by producers and consumers. The Schema Registry ensures that data produced and consumed by Kafka clients adheres to predefined schemas, enabling schema evolution and compatibility checks. By enforcing schema compatibility and evolution, the Schema Registry helps ensure data integrity and interoperability across different systems and applications.
Schema Registry provides the following services:
- Allows producers and consumers to communicate over a well-defined data contract in the form of a schema
- Controls schema evolution with clear and explicit compatibility rules Optimizes the payload over the wire by passing a schema ID instead of an entire schema definition At its core, Schema Registry has two main parts: A REST service for validating, storing, and retrieving Avro, JSON Schema, and Protobuf schemas Serializers and deserializes that plug into Apache Kafka® clients to handle schema storage and retrieval for Kafka messages across the three formats
At its core, Schema Registry has two main parts:
- A REST service for validating, storing, and retrieving Avro, JSON Schema, and Protobuf schemas
- Serializers and deserializes that plug into Apache Kafka® clients to handle schema storage and retrieval for Kafka messages across the three formats