1. Introduction
Natural Language Processing (NLP) is a field of artificial intelligence focusing on the interaction between computers and human languages. One of the fundamental challenges in NLP is converting textual data into a format that machine learning algorithms can effectively process and analyze. The Bag-of-Words (BOW) model is a simple yet powerful representation technique that plays a crucial role in this transformation.
The BOW model treats a document as an unordered set of words, disregarding grammar and word order but considering the frequency of each word’s occurrence. It represents a document by creating a “bag” (or vector) of words, where each word in the vocabulary is assigned a unique index, and the vector elements correspond to the frequency of each word in the document. The example below represents the text “The quick black dog jumps over the lazy dog” to the BOW model.
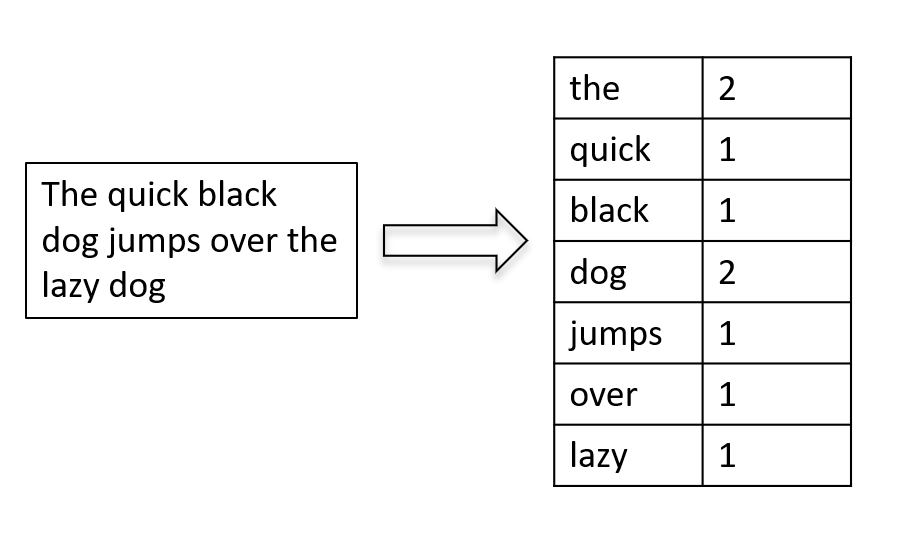
Creating a BOW representation involves tokenization, where the document is divided into individual words or tokens, followed by constructing a vocabulary based on all unique words across the entire corpus. Each document is then represented by a vector, with a dimensionality equal to the size of the vocabulary, and each element indicates the frequency of the corresponding word in the document.
Vector representations allow for mathematical operations, such as vector addition, subtraction, and dot product. This facilitates comparing and manipulating textual information, which is crucial for tasks like similarity analysis, clustering, and classification in Machine Learning Models.
2. Terminology
| Document | A piece of text or a collection of text that is considered as a single unit for analysis |
| Corpus | A large and structured collection of text documents. A corpus is used as a representative sample of a language or a domain, and it serves as the basis for various linguistic analyses, language modeling, and Machine Learning tasks |
| BOW vector | A numerical representation of a document or a piece of text based on the frequency of words |
| Preprocessing | Series of steps or techniques applied to raw text data before it is used for analysis or machine learning tasks such as removing stop words |
| Stemming and Lemmatization | A preprocessing technique to reduce words to their root form. Stemming involves removing prefixes or suffixes to get to the root, while lemmatization involves reducing words to their base or dictionary form. |
| Stopwords | Stopwords are common words (e.g., “the,” “and,” “is”) that often do not contribute much to the meaning of a sentence. Removing stopwords can reduce the dimensionality of the data and improve efficiency |
| Tokenization | A preprocessing technique breaking down a piece of text into individual units called tokens |
3. How does Bag-of-Words work?
In real work, we normally use BOW in a corpus that contains multiple documents and each document can have a different vocabulary set, so the BOW process is more complex than a single document like our above example. There are a lot of variants of BOW depending on the model and the system we need to build so the process can be different but here are the 4 basic steps.
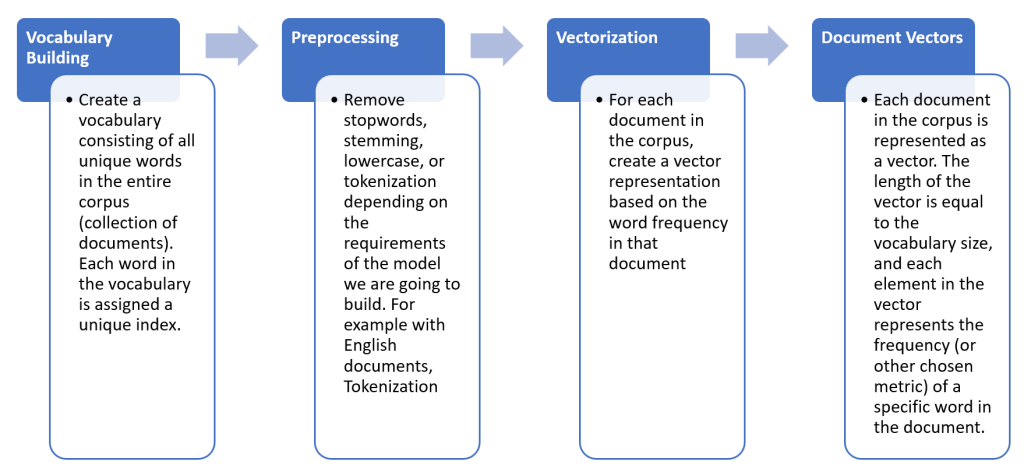
Let’s consider an example with two documents:
- D1: “Natural language processing is an exciting field of study”
- D2: “Studying NLP involves understanding various language processing techniques such as language detection”
We will convert these two documents into BOW vectors based on 4 steps above:
- Vocabulary Building: the vocabulary is [‘studi’, ‘detect’, ‘excit’, ‘natur’, ‘involv’, ‘variou’, ‘techniqu’, ‘process’, ‘nlp’, ‘languag’, ‘field’, ‘understand’]
- Preprocessing: remove stopword and apply stemming to each document:
D1 -> “nature languag process excit field studi”
D2 -> “studio nlp involve understand variou languag process techniqu languag detect” - Vectorization
D1: [{nature : 1}, {languag : 2}, {process : 1}, {excit : 1}, {field : 1}, {studi : 1}]
D2: [{studi : 1}, {nlp : 1}, {involv : 1}, {understand : 1}, {variou : 1}, {language : 2}, {process : 1}, {techniqu : 1 }, {detect: 1}] - Document Vectors: the BoW vectors for these documents would be:
D1: [0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0]
D2: [0, 1, 0, 0, 1, 1, 1, 1, 0, 2, 0, 1]
4. Bag-of-Words benefit and limitation
The BOW model offers several benefits in natural language processing (NLP) and text analysis tasks:
- Simplicity: BOW is a simple and intuitive representation of text data. It’s easy to understand and implement, making it a good starting point for text-based projects, especially for those new to NLP.
- Compatibility with Machine Learning Algorithms: BOW vectors provide a numerical representation of text, which is essential for applying machine learning algorithms. Many machine learning models, including traditional classifiers, support vector-based inputs, and BOW vectors serve as a straightforward way to represent text data in a format suitable for these algorithms.
- Scalability: BOW is scalable and can be applied to large datasets. It simplifies the representation of documents, allowing for efficient storage and processing of textual information.
- Flexibility in Text Analysis: BOW can be used for various text analysis tasks, such as document classification, sentiment analysis, and information retrieval. Its simplicity makes it applicable to a wide range of NLP applications.
- Interpretability: BoW vectors are interpretable, as each element represents the frequency of a specific word in the document. This transparency can be beneficial for understanding which words contribute most to the representation of a document.
- Preprocessing Opportunities: BoW allows for the incorporation of various preprocessing techniques, such as removing stopwords, stemming, and handling term frequency–inverse document frequency (TF-IDF) weighting. These preprocessing steps can improve the quality of the representation and enhance the performance of models.
- Baseline Model: BoW can serve as a baseline model for text analysis tasks. More advanced models, such as word embeddings or transformer-based models, can be compared against the baseline performance achieved by BoW. This helps assess the value of more complex models in specific scenarios.
Besides a lot of benefits, there are still some limitations of BOW including:
- Loss of Word Order: BoW ignores the order of words in a document, which means it fails to capture the sequential and structural information present in the text.
- Semantic Information Loss: BoW cannot represent the semantic relationships between words. Synonyms or words with similar meanings may be treated as distinct entities.
- High-Dimensional Representation: BoW vectors can result in high-dimensional, sparse representations, especially when dealing with large vocabularies. This can lead to computational inefficiencies and increased memory requirements.
- No Consideration of Context: BoW treats each word independently and does not consider the context in which words appear. The same words in different contexts may have different meanings, but BoW treats them identically.
- Limited Handling of Polysemy: Polysemy (multiple meanings for a single word) can be challenging for BoW, as it may not differentiate between different senses of a word based on context.
- Fixed-Size Representation: BoW creates fixed-size vectors for each document, which can be limiting when dealing with variable-length texts. Longer documents may lose information, and shorter documents may lack context.
- Inability to Capture Phrase-Level Information: BoW treats each word as an independent feature, making it difficult to capture meaningful information at the phrase or subword level.
While BoW has its drawbacks, it serves as a useful baseline model in NLP. More advanced techniques, such as word embeddings and transformer-based models, have been developed to address some of these limitations and capture richer semantic relationships in text data.
5. Demo
To practice BOW, I use Python with nltk library which supports all steps relating to BOW.
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
import nltk
from typing import List
nltk.download('punkt')
nltk.download('stopwords')
def bow(documents: List[str]):
bow_vectors : List = []
vocabulary = set()
stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
for document in documents:
# Tokenization
document = word_tokenize(document)
# Stopwords removal
document = [word for word in document if word.lower() not in stop_words]
# Stemming
document = [stemmer.stem(word) for word in document]
# Create vocabulary
vocabulary.update(document)
# sort vocabulary alphabetical to make to result predictable
vocabulary = sorted(list(vocabulary))
for document in documents:
# Bag-of-Words representation
bow_vectors.append([document.count(word) for word in vocabulary])
return {"bow_vectors": bow_vectors, "vocabulary": vocabulary}
# Sample documents
document1 = "Natural language processing is an exciting field of study"
document2 = "Studying NLP involves understanding various language processing techniques such as language detection"
print(bow([document1, document2]))
# will print: {'bow_vectors': [[0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0], [1, 0, 0, 1, 2, 0, 0, 1, 0, 1, 1, 1]], 'vocabulary': ['detect', 'excit', 'field', 'involv', 'languag', 'natur', 'nlp', 'process', 'studi', 'techniqu', 'understand', 'variou']}
6. Conclusion
In conclusion, the BOW model has been a foundational and widely used technique in NLP. Despite its simplicity and certain limitations, BOW provides a practical approach to representing textual data for various NLP tasks. By converting documents into vectors based on word frequencies, BOW facilitates the application of machine learning algorithms to analyze and classify text. Its interpretability and ease of implementation make it a suitable choice for baseline models in text analysis.
However, it’s essential to acknowledge BOW’s shortcomings, including the loss of word order, semantic information, and the inability to capture context. As NLP continues to advance, more sophisticated models like word embeddings and transformer-based architectures have emerged, addressing some of these limitations and capturing richer semantic relationships in text.
The choice of representation, whether BOW or more advanced methods, depends on the specific requirements and nuances of the NLP task at hand. BOW remains a valuable starting point for understanding text analysis techniques, and its historical significance underscores its role in the evolution of NLP methodologies. This sample project can be found on GitHub.