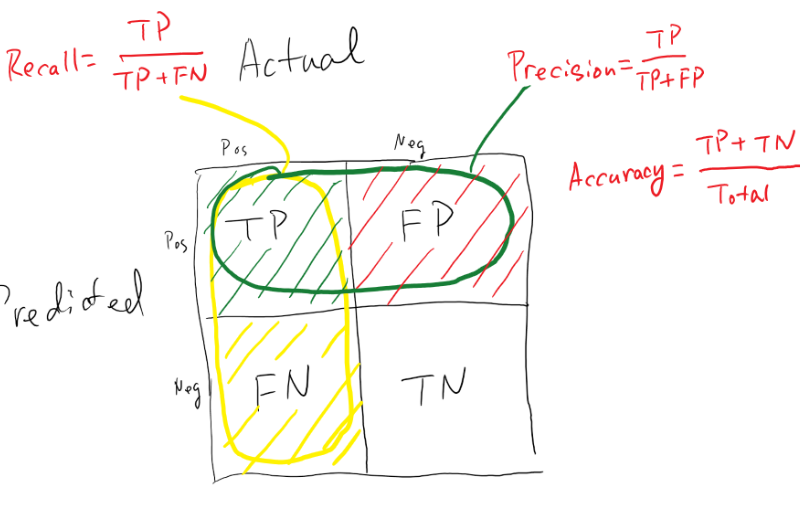
1. What is full-text search?
Full-text search (FTS) is a technique for searching a collection of documents for relevant results based on the presence of certain words or phrases. FTS is a branch of information retrieval and also relates to text mining and natural language processing.
FTS uses an index – a special data structure of all the words present in all the documents to quickly locate results. It can also be used to search for documents that contain words or phrases that are similar but not exactly the same.

FTS is especially useful when dealing with large collections of documents or a large number of queries that provide ranked search results. FTS is used in a variety of applications, including web search engines, online databases, social media, and enterprise search solutions.
2. Compare Full-Text Search queries to the LIKE predicate. Some popular full-text search engines
FTS queries are more powerful than the LIKE predicate (e.g. SELECT * FROM employee WHERE name LIKE ‘Nguyen%’). The LIKE predicate can only search for exact substring matches, while FTS queries can use multiple operators to match words, phrases, and even similar words.
Additionally, FTS queries can be used to search for multiple words at once and can return ranked results that match multiple words, LIKE predicate can not rank results.
Ranking is really important factor that help us to know which results are relevant the most and can be utilized in text similarly area by a “score” assigned to each result.
FTS queries are also more efficient than the LIKE predicate, thank for FTS index that makes FTS must faster than the LIKE predicate (for example Google can reply to your query in only a few seconds with million returned results)
3. Some popular full-text search engines
The most popular full-text search engines are Apache Lucene, Apache Solr, Elasticsearch, and Sphinx. All of these search engines are open source, and they are all built on top of Lucene. Each of them has its own unique features and advantages, but they all provide powerful, scalable full-text search capabilities.

I won’t dive deep into these engines on this topic because this topic is about the background of full-text search so I will just talk about full-text search concepts and some full-text search models.
4. FTS basic model
Before diving deep into FTS basic model, we need to understand FTS input and output from end-user perspective.
FTS input:
- Documents: a document or set of documents that are used to store and retrieve information. FTS documents are typically created and maintained by a computer program or system and are used to store information such as web content or social posts.
- Query: a request made to an FTS system to retrieve documents that match a specified set of criteria. A query typically takes the form of a keyword or phrase, and the documents retrieved are those that contain the specified keywords or phrases (such as “spring framework” as in the above image).
FTS output:
- Results: relevant ranked documents with the search query
For example, we build an FTS system for a library that has 100 books (documents) to search for relevant books by content. A user accesses this FTS system and searches “mafia books” (query), then the system returns the top 3 relevant results ranked by a score (0 to 1) are:
- The Godfather (0.96)
- The Sicilian (0.8)
- The Last Don (0.7)
The basic model of FTS consists of two basic stages, indexing and retrieval. A basic FTS system works based on the main components which are:
- A lexical unit (term) to represent documents and queries
- The matching function is used to map documents and queries
- Models represent documents and queries
4.1. Bag of words model
Bag of words (BOW) is a document representation method used by most FTS systems. With BOW, the documents are indexed based on the words and in order to retrieve the information, the words in the query must appear in the index.
The main idea of BOW contains two steps:
- Representing a document based on the frequency of occurrence of words
- Building a “feature vector” for the document with each element being a “weight” representing the importance of the word/term
Let’s dive into a straightforward example to understand how BOW works with two simple documents:
D1: “The cat sat on the car”
D2: “The dog ate the cat and the car”
From the above two documents, we have a vocabulary set: {the, cat, sat, on, car, dog, ate, and}.
Applying BOW to represent these two documents:
- in D1 for each word/term in the vocabulary we have: “the” appears twice, and “cat”, “sat”, “on”, and “car” Each word appears once, the remaining three words do not appear, so the feature vector with D1 will be: { 2, 1, 1, 1, 1, 0, 0, 0 }
- Similarly, the feature vector for D2 is: { 3, 1, 0, 0, 1, 1, 1, 1}
At the indexing stage, the documents will usually go through a pre-processing step such as removing stop words, stemming, etc., with the aim of reducing the size of the index to be stored.
4.2. Vector space model
Vector Space Model (VSM) is the improved version of BOW where each text document is represented as a vector using an algebraic model.

Most full-text search engines use VSM as the core model, and some of them combine VSM with other models.
Lucene uses a combination of the VSM and the Boolean model.
The idea of VSM is similar to BOW but the weight of each word is calculated in more detail. The VSM is constructed to have separate dimensions for each distinct word aggregated from all BOWs in the documents.
In VSM the weight is calculated based on the famous formula tf.idf (term frequency-inverse document frequency)

In VSM, vocabulary i with high weight will be words that appear frequently in document j but rarely appear in other documents.
In VSM, we denote T as a set of all vocabularies contained in the corpus (set of words): T= {Term1, Term2,…, Termt}, T = {ti}, i [1,..,t]. Based on the weight calculation using the formula tf.idf, VSM represents the document as a point in the vector space defined on T, each dimension corresponds to a word in the set of words.
5. The common architecture of a full-text search system
The entire full-text search system is as above including two stages indexing and retrieval, both documents and queries need to be preprocessed (remove stop word or stemming) as I mentioned earlier.

Indexing stage
Based on VSM we get an index matrix representing the document-vocabulary relationship in the corpus.

Normally, most full-text search engines store this index matrix in encoded files. If you want to replicate your full-text search application, you only need to replicate these files. The image below is an example of Lucene index files.

Retrieval stage
At the information retrieval stage, we also represent the feature vector for the query similar to the representation for the vocabulary, then calculate the similarity of each document in the repository with the query using a matching function – Cosine similarity.
The similarity of the document and the query is calculated using the Cosine similarity for their two feature vectors, also known as the document’s score in the query.

The more relevant documents are to the query, the higher the score will be so that we will retrieve the set of documents most relevant to the query.